Ancient Greek OCR
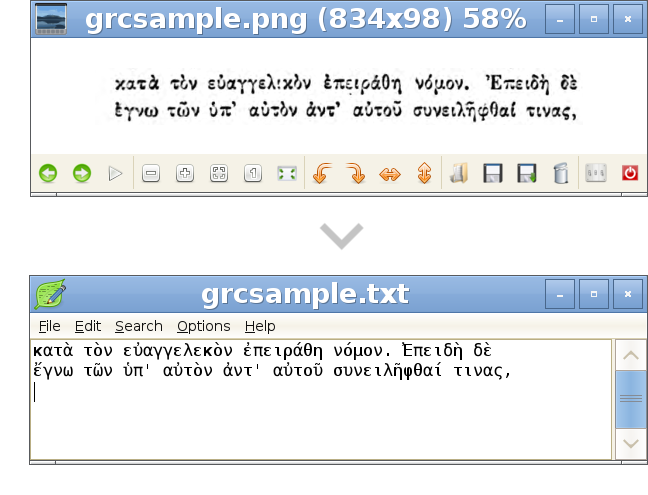
Ancient Greek OCR is free software to accurately convert scans of printed Ancient Greek into unicode text and PDF files, which can be easily searched, copied, archived, and transformed. It uses the excellent Tesseract OCR engine, tailored for Ancient Greek typography, syntax and vocabulary.
It works with Windows, OS X, Linux and Android, and works on personal computers, mobile devices, and large server clusters.
Download
Ancient Greek OCR v2.0 (2014-05-01)
Instructions: Windows | OS X | Linux | Android
How it works
Training Tesseract for Ancient Greek OCR article published in The Eutypon 28-29.
Release history
- 2.0 (2014-05-01)
- Use new Tesseract tools to generate training images. Sample characters at different exposure levels. Remove rare characters (†/ϙ/ʹ). Add speech marks (“/”). Replace accented characters in modern Greek unicode set (U+0370) with Ancient Greek (U+1F00) variants. Improve wordlists by properly registering upper / lower case complements. Improve wordlist generation from Perseus corpus. Improve punctuation rules. Add rules to convert some apostrophe detections into breathing marks. Build is completely deterministic.
- 1.4 (2013-04-04)
- Significantly improve line segmentation. Improve diphthong breathing mark correction rules.
- 1.3 (2013-02-28)
- Add noise to training texts to improve recognition for lower quality scans. Improve diphthong breathing mark correction rules. Improve accent ambiguity rules. Add several miscellaneous ambiguity rules.
- 1.2 (2012-10-24)
- Add rules to correct rho breathing mark errors
- 1.1 (2012-10-23)
- Improve dictionary scoring.
- 1.0 (2012-09-13)
- Initial release.
The code
All of the code used to generate and test the Ancient Greek OCR training data is free software released under the Apache License 2.0.
- git clone https://ancientgreekocr.org/grctraining.git
- Rules and tools to deterministically generate the Ancient Greek training for Tesseract.
- git clone https://ancientgreekocr.org/grcground.git
- Ancient Greek page scans and ground truth text for testing OCR accuracy (note that this repository is about 4.5GiB).
- git clone https://ancientgreekocr.org/ocr-evaluation-tools.git
- Tools to test OCR accuracy.
Old repositories
There are several old repositories which are kept around in case they are useful to people, but have been superceded by the above repositories.
- git clone https://ancientgreekocr.org/grc.git
- The final training process, which used files generated by the grctraining repository. All of this functionality is now included in the grctraining repository.
- git clone https://ancientgreekocr.org/grctestfodder.git
- Ancient Greek page scans and ground truth text for testing OCR accuracy (far fewer than is now included in the grcground repository above).
Contact
For comments, bugs, criticisms, code, help, or anything else, contact Nick White at ancientgreekocr@njw.name.
Thanks
This project was made possible in part by the Institute of Museum and Library Services, LG0611032611; the National Endowment for the Humanities: Exploring the human endeavor; and the Perseus Digital Library Project, as well as the ERC funded Living Poets Project. The Tesseract OCR engine makes this all possible, doing all of the hard work behind the scenes.
Related projects
Lace is a project publishing high quality OCR on scans of Ancient Greek from archive.org.